
Mapping Out the Requirements

Infra as Code (IaC) | AWS Hero | Teacher | Mentor | Youtuber | -> Way to Cloud & MLOPS
Introduction
In this blog, we are going to talk about mapping out the requirements. Specifically, we're going to talk about our machine learning operation scenario and some first steps. We're also going to map out some core requirements and introduce pipelines and sketch out the basic steps that you need to know.
Mapping out the requirements
Well, in order to get started as a machine learning operations engineer with this, the first thing that you need to do is understand the business need. We always start here. You need to ask questions. You need to ask lots of questions, and then you need to document and map out the requirements. So, what do we have? What sources are we ingesting? What are we trying to accomplish? So, in this scenario, what we're trying to accomplish is we have a list of information about restaurants we want to understand customers preferences as they go into a restaurant to give us a better idea of what kind of restaurants we should build. So, with that, we have the business need.
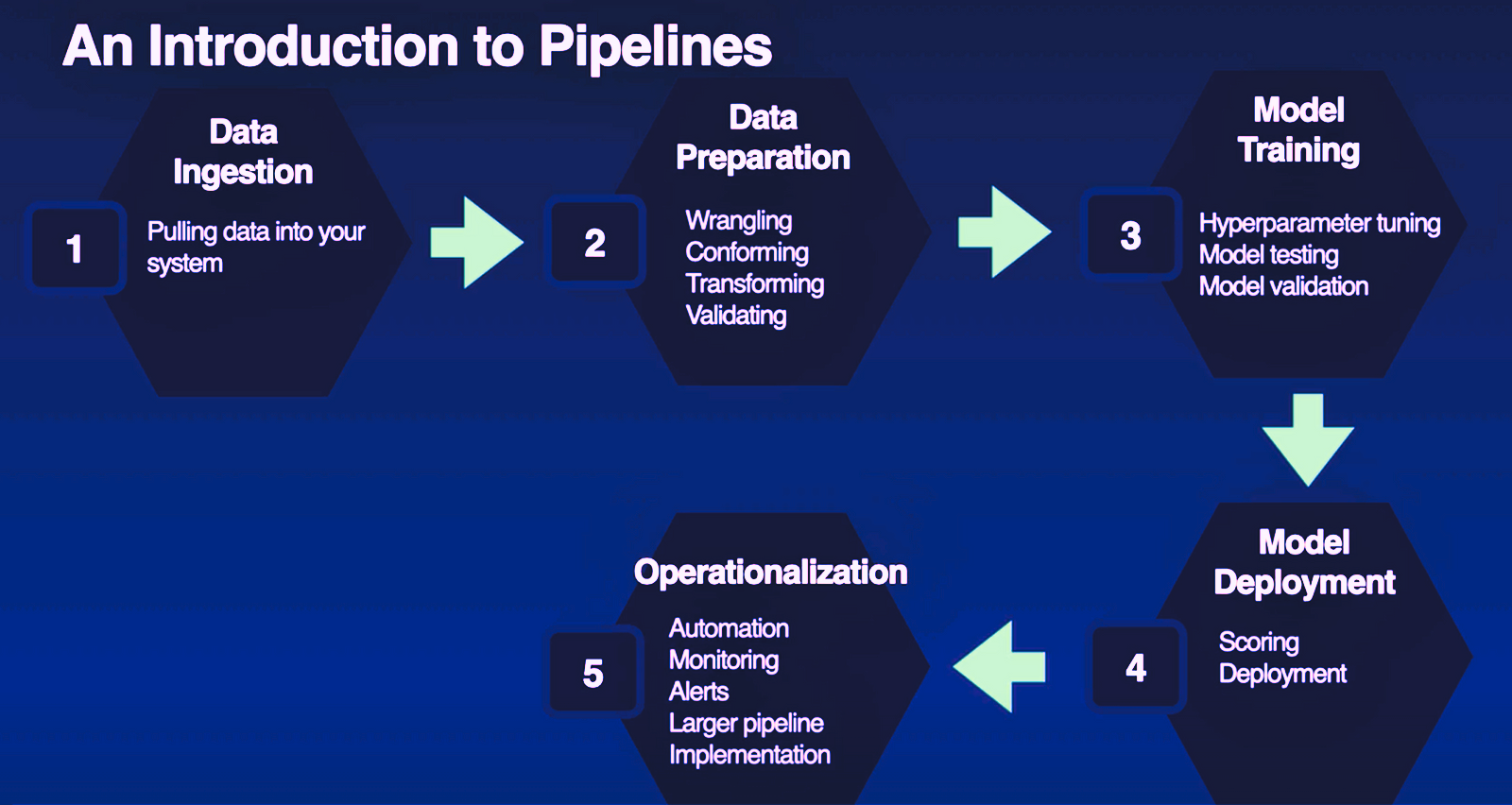
"What's a pipeline?" So, let's go through some of the basics of pipelines. We start by data ingestion. So, data ingestion is just going to be us pulling data into our system.
Then, we're going to go to data preparation. Data preparation is going to include wrangling, conforming, transforming, validating. Basically, what it means is we got a whole bunch of different data sources that are being pulled into the cloud, and we need to make sure that all of those data sources are cleaned up, there's not errors, that all of those data sources look similar in the way they talk about data. And then we can use that to go into our model.
And in model training, we're going to talk about hyperparameter tuning. We're going to talk about model testing and model validation. So basically, we're going to pick the pieces of data that we need, pull those into our model, we're going to make little tweaks to the model and then we're going to test and validate that model there.
Once we got all that done, we're going to do model deployment. So, model deployment is where we actually score and then deploy our models. Again, kind of making sure that we have what we need and then pushing that in, so that we can operationalize, which is the last step which is the automation: the monitoring, the alerts, the larger pipeline implementation.
Basically, once we're all the way done, we want to be able to take what we've done from that model deployment, and we want to be able to scale that to use that model when we need to to be able to do the next step, which is get a report or get information that can help us to make the decisions.
In the case of our scenario, we want to understand again which restaurants we would choose. So, we want some reports or some data that's going to help us to make those decisions.
We start out by writing what the business need is and what the goal is, and then as we move through each of the steps, we say, "Is that in line with the business goal? "Does it help us to achieve what we need to achieve?" If the answer is no, then do we really need it? Then we start by moving through the steps.
1. Ingestion
Know what data is needed.
How often do we need that data?
We need it in real time?
Can we pull it in once a week, once a month?
2. Preparation
So, as we transform that data, we look at the data sources and the columns, and understand what we would need to do to get that data into a usable piece of information that we can use in our machine learning pipelines.
3. Training
What's the algorithm?
How do we use hyperparameter tuning?
What kinds of things are we going to do to our model to make sure that we are training it appropriately?
4. Deploying
So, once we have it deployed, where's it going to go?
4. Operationalization
So, who's going to manage it?
Who's going to manage the alerts?
Who's going to create the alerts?
Who's going to look at monitoring?
Who's going to make sure the pipeline is up and running efficiently?
Key points to remember
- Always start with the business goal.
- Don't let somebody tell you otherwise.
- Don't jump into the portal and just start creating.
- And never start without a plan.
I hope this blog has been helpful. I'll see you in the next blog.




